Assessing the Efficacy of Measuring Diagnostic Reasoning
by Christopher Cimino, MD, FACMI, VP of Medical Academics, Kaplan Medical | September 20, 2021

Have we made any progress in the last 200 years in how doctors are trained in diagnostic reasoning? The modern approach is certainly different from past training methods in terms of being more formalized and structured; but in essence, it is a centuries-old apprenticeship model (1). We might rest assured that diagnostic accuracy has improved, if for no other reason than advances in diagnostic technology, but we also know that diagnostic error remains a significant portion of medical errors leading to morbidity and death. Surely, there should be a desire to improve the human factor in diagnostic reasoning. But, without a way of measuring diagnostic reasoning in a standardized way, attempts at improvement will remain guesswork. A recent publication in Diagnosis, “Use of a structured approach and virtual simulation practice to improve diagnostic reasoning,” (2) makes some interesting and illuminating in-roads on the problem of measurement.
The Challenges Of Measuring Diagnostic Reasoning
For decades medical students have had their diagnostic reasoning tested with multiple choice questions (MCQs). For a decade and a half, it was also measured nationally using standardized patients (SPs). I don’t think anyone thought MCQs were the best way to measure diagnostic reasoning, but it was justified by the mantra that “multi-jump equals reasoning.” SPs were better because they assessed diagnostic reasoning in a setting as close to a real-world setting while also providing standardization. However, there remained subjectivity in how checklists were created (creator bias) and were completed (grader bias), but with training, grader bias should be minimized. Standardization is important because it leads us to reproducible results and the ability to make comparisons.
Sadly, the ability to compare nationally was compromised by the fact that only pass-fail information was available. MCQs provide that quantitative comparison, but clearly the two approaches are measuring different things. Admittedly, the purpose of these national exams was always to measure minimal competency for licensure. With USMLE Step 2 CS and COMLEX-USA Level 2 CE discontinued, we have lost the SP national standard. It was important because it was a strong motivator for schools to develop their own clinical skills assessment programs. Hopefully, those will resume at individual schools but they will only provide a way to compare students within a school―not nationally. Without the motivation of a national standard, will schools resume with the same rigor? The cost savings to cut corners will be very tempting.
What Should the Gold Standard Be?
The AAMC Group on Educational Affairs has made a call for participants in “The CLASS Project to Develop National Standards for Clinical Skills” (3). It is an ambitious effort looking to define a national standard not just for undergraduate medical education (UME) but graduate (GME) and beyond (CME.) A key question to be answered is “What should the gold standard be?” MCQs provide a reliable way to create a quantified standard, if not an accurate one. SPs provide what is likely a more accurate standard, but allows for some subjectivity and it’s less clear how it should be quantified. It is certainly a more expensive approach.
The Diagnosis paper is timely and interesting in that it proposes both an alternative approach to measuring diagnostic reasoning and an alternate approach to training. The alternate measurement approach relies on a virtual standardized patient experience using i-Human Patients by Kaplan (iHP.)
Examining i-Human Patients for Measuring Diagnostic Reasoning
What are the pros and cons of iHP? It removes the grader bias. Two students going through a virtual case who happen to make the exact same choices will always be evaluated the exact same way. While an SP checklist removes some of the subjectivity, in any open interaction reliant on natural language, there will always be a matter of interpretation. Does “that” utterance deserve a “yes” or a “no” on “this” checklist item. Training can reduce but can not eliminate grader biases, while iHP does eliminate that bias. iHP could include natural language processing. It might make mistakes, but it will consistently make the same mistakes.
The other obvious difference between the SP and the iHP is that we are taking a step away from matching the experience to reality. Is it too big a step away? This shouldn’t be an isolated judgment, because clearly there will always be room for improvement, but there will always be trade-offs. Figure 1 is a conceptual view of how all these factors are related. For example, an existing screen simulation that has sound and motion can be improved with a virtual reality interface, but at an added cost. In fact, it is easy to see that the fidelity of the interaction is going to increase the realism of a simulation at the same time it increases the cost. My own experience has been that fidelity improvements often follow an exponential cost curve. (The exception here is the cost of “real patients” which ventures into the topic of affiliation agreements which is beyond the scope of this discussion.)
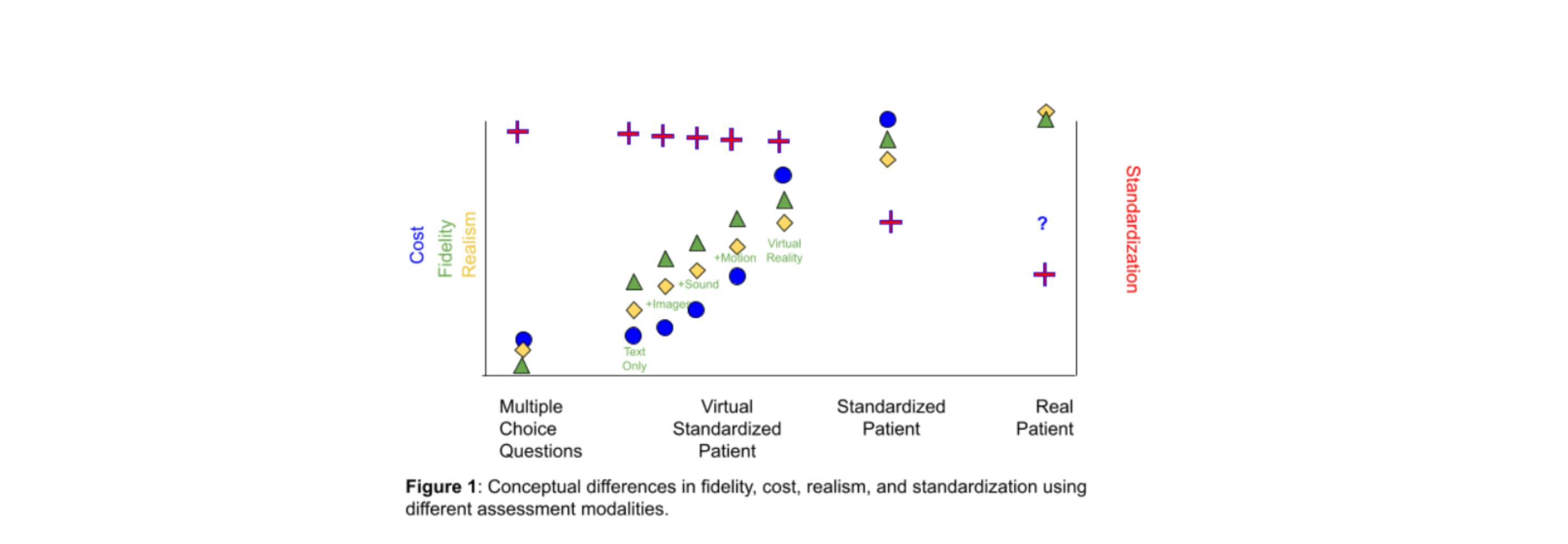
There will also be a change in the standardization of the assessment. A real patient will be the least standard, being in an uncontrolled environment and not a reproducible experience, even with the same patient on the same day. An SP is an improvement. The other approaches eliminate grading bias, and what remains is the creator bias. That creator bias is likely similar for all these assessment types, except that limiting the fidelity limits the opportunities where bias can be introduced. MCQs are likely more standard precisely because they are less realistic.
Diagnostic Accuracy, Efficiency, and Completeness
Having explored the modalities to measure diagnostic reasoning, how do we define “diagnostic reasoning”? The Diagnosis paper provides a good starting point in defining accuracy, efficiency, and completeness. Sometimes the modality limits the definition. MCQs by design have the student find the “single best answer.” What is the “right” diagnosis? The Diagnosis paper uses a pre-test and post-test set of MCQs to measure this traditional definition of diagnostic accuracy. After all, that is the current mode available nationally. However, this is a terrible way to assess diagnostic accuracy. It promotes premature closure, recognized as an important source of medical error (4). The cure for premature closure is having a differential diagnosis and the goal is to ensure that the correct diagnosis is accounted for in the work-up and management plan.
Simply defining diagnostic accuracy as having the right diagnosis in the differential also encourages behavior counter to the diagnostic process. In considering a patient who presents with delirium, students would be encouraged to list dozens or hundreds of potential diagnoses to increase their “diagnostic accuracy” by including the “correct” diagnosis. This would do little to guide the practical management of a real patient with delirium. MCQs also encourage creators to ignore more complex cases where more than one diagnosis should be considered. To counteract these issues we need to define “diagnostic efficiency” and “diagnostic completeness."
The Diagnosis paper defines completeness and efficiency as follows:
Completeness is the percentage of “appropriate diagnoses” included in the differential, where appropriate is defined by the assessment creator.
Efficiency is defined as the percentage of appropriate diagnoses that make up the examinee’s differential diagnosis.
So, if there are 3 appropriate diagnoses and the student lists exactly those 3 they get 100% for completeness and efficiency. If they list 5 diagnoses of which one 2 are considered appropriate, they get a 66% for completeness and a 40% for efficiency. There could be more nuanced measurement methods making use of points or ranking schemes for more or less important diagnoses.
My observation is there is frequent disagreement on relative ranks between experts, so the simpler global approach from the Diagnosis paper has some advantages here. The problem becomes more complicated when the experts start discussing what name items in the differential. The International Classification of Disease can provide a standard but the departure from that standard in medical records often serves a useful communication purpose. Syndromes capture some grouping and uncertainty in the differential in a useful way not possible by using just the standard terms.
Not surprisingly, the Diagnosis paper showed that a formal approach to teaching diagnostic reasoning and having students do practice cases shows measurable improvement in student diagnostic accuracy, efficiency, and completeness. I foresee many readers also saying, “I’m not surprised.” That shouldn’t undermine the importance of this study. It is. unfortunately. common to many early studies. Faculty at the participating schools felt strongly that not providing these interventions would put the control group at a disadvantage. What would be the most ethical way to test these interventions when there is so little evidence? This study provides that first brick of information on which further studies can be built. It suggests a host of theoretical questions to be explored. Is this a better way of teaching diagnostic reasoning?
Before theoretical questions can be answered, there are a host of empirical questions that would be useful to answer. What are the average diagnostic accuracy, efficiency, and completeness of trainees and physicians at different points in their training and career? It is only by establishing those baselines that we can measure whether a teaching method is more efficient.
REFERENCES
- The Physician Apprentice. https://medicine.yale.edu/news/yale-medicine-magazine/the-physicians-apprentice/
- Dekhtyar et al. Use of a structured approach and virtual simulation practice to improve diagnostic reasoning. Diagnosis, The Official Journal of the Society to Improve Diagnosis in Medicine. Pre-published online by De Gruyter July 12, 2021. https://www.degruyter.com/document/doi/10.1515/dx-2020-0160/html
- Gabbur, N. CLASS Project Deadline Approaching!! DR-ED Mailing List Archives, August 28th. 2021. https://list.msu.edu/cgi-bin/wa?A0=DR-ED
- Croskerry, P. The Importance of Cognitive Errors in Diagnosis and Strategies to Minimize Them. Academic Medicine: August 2003 - Volume 78 - Issue 8 - p 775-780. https://pubmed.ncbi.nlm.nih.gov/12915363/

Dr. Cimino has earned a reputation internationally as an award-winning medical educator. He was the founding Assistant Dean for Educational Informatics at Albert Einstein College of Medicine and former Associate Dean for Student Affairs at New York Medical College. He is board certified in Neurology and Clinical Informatics. He served as a member of the NBME Step 1 Behavioral Science Committee and the NBME End of Life Care Task Force.
See more posts by Christopher Cimino, MD, FACMI, VP of Medical Academics, Kaplan Medical